AI 基础概念
曦子起源
现在 AI 是风口浪尖, 但其实生成式人工智能模型这项技术的发展已经几十年了,最早的研究可以追溯到 60 年代. 最早期也是聊天机器人, 依赖于专家提取的知识库, 知识库的答案则靠问题的关键字触发, 不过这种局限性很强.
机器学习(A statistical approach to AI: Machine Learning)
20 世纪 90 年代,统计方法开始应用于文本分析, 这就催生了新算法 机器学习, 这种算法无需明确编程, 便能从数据中学习模式。这种方法使机器能够模拟人类的语言理解:统计模型在文本标签配对上进行训练,使模型能够使用代表消息意图的预定义标签对未知输入文本进行分类。
神经网络 (Neural networks)
这几年硬件发展迅速, 就产生了更高级的机器学习算法, 就是大家周知的 神经网络(neural networks) 或者说 深度学习(deep learning). 神经网络,特别是 RNN 增强了自然语言的处理能力,能够重视句子中关键词的上下文(记忆机制)。不过 由于 RNN 需要对序列中的每一个时间步骤进行反向传播,导致它容易出现梯度消失(Gradient Vanishing)和梯度爆炸(Gradient Exploding)问题。这是因为随着时间步数的增加,梯度会逐渐消失或变得过大,导致模型训练困难。
现在的生成式 AI (Generative AI)
经过数十年的人工智能研究,一种名为 Transformer 的新模型架构克服了 RNN 的限制,能够获得更长的文本序列作为输入。Transformer 基于注意力机制,使模型能够为收到的输入赋予不同的权重,无论文本序列中的顺序如何,都会“更加关注”最相关的信息集中的地方。
你可以把现在的 AI 当成深度学习的一个子集。
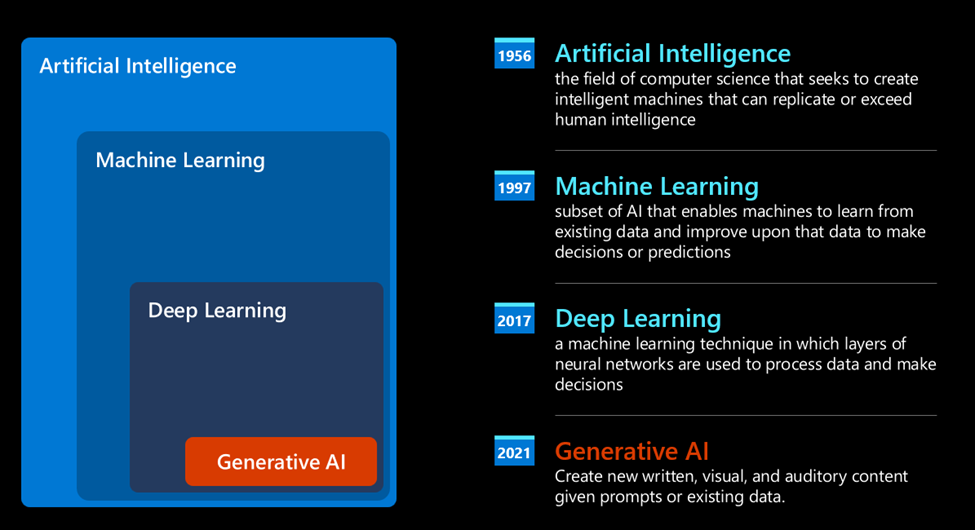
现在的生成式 AI (也就是 LLM), 的特点在于使用来自书籍、文章和网站等各种来源的大量未标记数据进行训练,可以适应各种各样的任务,并生成具有一定创造性的语法正确文本。
大模型如何工作?
首先我们先理解几个概念, 也是经常能看到的术语.
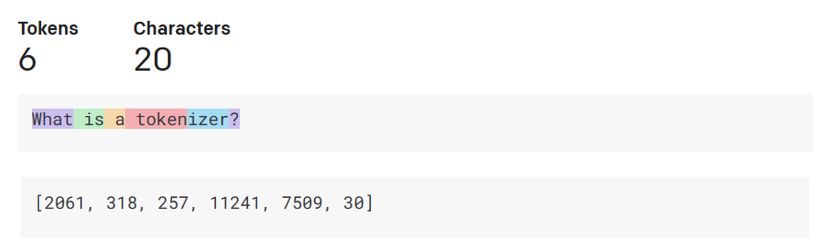
- Tokenizer 分词器: 大模型作为统计模型, 处理数字的能力远高于普通文本. 所以模型的输入在被模型使用之前会被分词器先处理. 而 Token 就是一个不固定长度的字符(一般来说都是数字), 简单来说分词器(Tokenizer) 就是把输入文本转成 token 数组. 每个 token 都有一个索引映射到之前的文本。可以在GPT Tokenizer 自己输入文本观测下 GPT 是如何分词的, 可以留意下符号跟词缀的处理.
- Predicting output tokens 预测输出标记: 有些同学可能在用 LLM 比如 ChatGPT 的时候发现有时候他在停顿, 这是因为大模型给定 n 个 token 作为输入(最大 n 因模型而异),模型能够预测一个 token 作为输出,然后这个 token 会以扩展窗口的形式被纳入下一次迭代的输入.
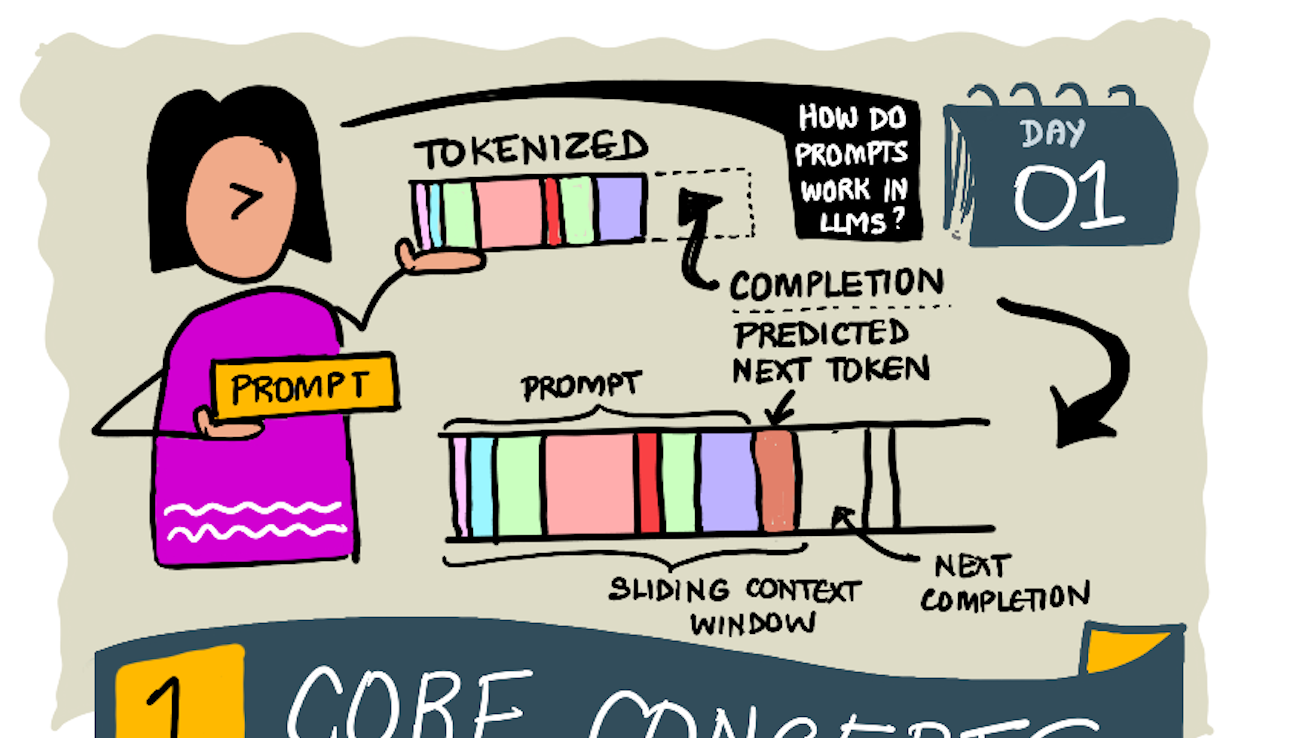
- Selection process, probability distribution 选择过程 概率分布: 模型会根据 token 出现的概率来选择下一个 token, 但是并不是概率高的 token 一定会被选择, 会有一定的随机性(或者说是创造性), 这样模型就会出现非确定性行为, 也就是同样的问题可能得到不一样的回答。这个随机性可以通过temperature(温度)的模型参数进行调节.
什么是输入和输出?大型语言模型的输入被称为提示词(prompt),输出则称为补全结果(completion),这个术语源自模型通过生成下一个标记(token)来完成当前输入的机制. 那什么是 instruction? 即告诉模型你期望得到什么输出, instruction 里可能包含示例。
不同类型的大模型
- 语音类: 针对这一用途,Whisper 类模型是绝佳选择,因其属于通用型语音识别模型.
- 图像类: DALL-E 和 Midjourney。
- 文本生成: 执行的 GPT、deepseek 等。
- Multi-modality 多模态: 多模态是指能同时处理多种类型的数据输入与输出,比如同时处理自然语言和图像,比如 gpt-4 turbo with vision.
基础模型 Foundation Models vs LLM
由斯坦福研究人员提出,并定义为符合某些标准的人工智能模型。也有些叫做基座模型。他们有如下特点:
- 通过无监督学习或自监督学习进行训练, 这意味着模型基于未标注的多模态数据进行训练,且训练过程无需人工标注或数据标签。
- 非常大,基于数十亿参数训练的深度神经网络构建的极大规模模型。
- 作为其他模型的基础,作为其他模型构建的起点,后续可通过微调进行定制化开发。

到这里基本的模型模型概念就差不多了, 下面就介绍下应用方面的概念。
如何改善 LLM 的结果 (微调)
如果直接跟选择的模型交互, 那么它的回答完全取决于它自身训练过的知识, 它不具备确定性,也不值得信赖,因为虚构内容(如错误的参考文献、内容和陈述)可能与正确信息混在一起, 而且它会表现的非常可信, 这个时候如果是某些垂直领域或者模型本身知识库不足的情况下就需要一些调整。
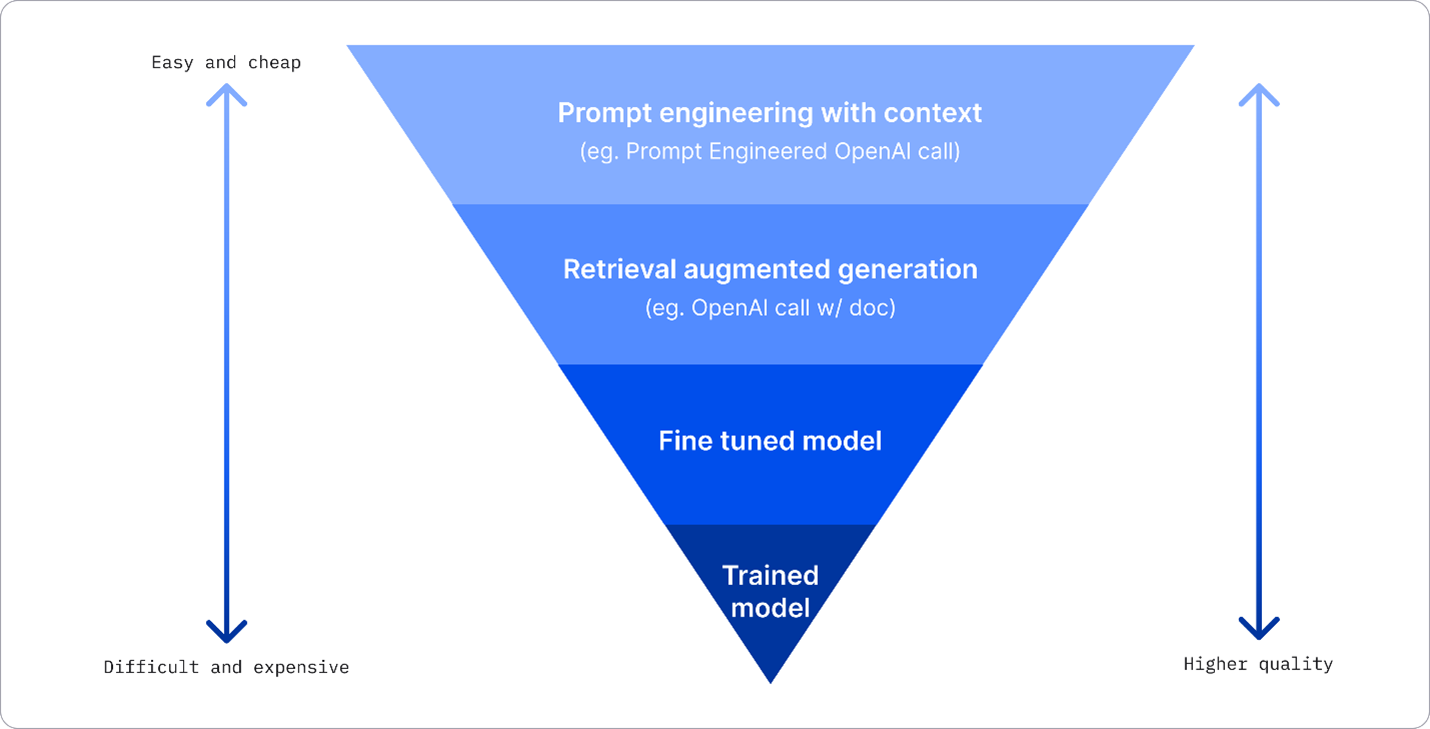
- Prompt Engineering with Context 上下文提示: 说白了就是你提供足够多的信息, 确保响应的预期。
- Retrieval Augmented Generation, RAG.: 大致就是把可信数据存到向量数据库, 确保 prompt 能包含这些数据, 然后把向量数据库检索的结果整合反馈给用户. 这种形式扩充了大模型的知识库, 也不需要频繁训练。
- Fine-tuned model.: 通过使用自有数据对模型进行进一步训练,使模型更精准响应特定需求,但可能产生较高成本。
Prompt Engineering with Context
预训练的模型很擅长处理自然语言, 仅通过简短提示(如补全句子或提出问题)进行调用——这种被称为zero-shot learning(零样本学习)的方式。如果能给出示例和详细的上下文, 那结果就会更精确, 如果仅包含一个示例那么就叫”one-shot”学习, 包含多个示例称之为”few shot learning”. 这种方式也是比较简单入门的方法。
Retrieval Augmented Generation (RAG)
之前也有提到, LLMs 只能使用训练期间用的数据生成答案, 也没办法访问公开数据. RAG 通过把外部数据 chunk 化, 放到向量数据库, 用文档片段的形式进行补充, 来解决这些问题, 还能兼顾提示语的长度(仅检索相关的片段)。一般情况下这对改善模型混淆现实和胡编乱造很有作用。
Fine-tuned model 微调模型
Fine-tuned 利用 transfer learning 来适配特定领域问题。微调会生成一个权重(weights)和偏置(biases)不同的新的模型,这样的话就需要我们准备多组训练数据, 每个训练数据要包含一个输入(prompt)及其对应的输出(completion). 通常用 QA 的形式提供, 可以看下数据结构:医疗训练数据. 以下几个场景我们可以考虑选用 Fine-tuned:
- Using fine-tuned models: 选用小模型, 很多高性能模型成本不划算, 说白了喂了太多无关内容, 但是依然是成本。
- Considering latency: 延迟问题, 可能 prompt 过长, 导致提示速度也慢。而且 prompt 过长本身也是问题, fine-tuned 把知识固化在模型里,就不需要超长的 prompt 教模型该怎么处理.
- Staying up to date 实效性: 如果有大量有效的数据, 定期训练就能解决这个问题.
Train Model
大规模训练消耗大量的计算资源, 数据资源, 一般不考虑这种 case.